




Let’s start with a quick game - consider that you have a deck of 52 cards, four suits - Ace through King. If I shuffle the deck into random order and ask you to pick out the 8 of hearts, you would have to individually flip through each card until you find it. This means that on average you would have to go through half the deck, which is 26 cards!
Now, consider that we divided the cards into four piles by suit, each pile shuffled randomly. Now if I asked you to pick out the 8 of hearts, you would select the pile with the hearts suit, which would take on average two to find, and then flip through the 13 cards. Approximately, it would take seven flips to find, thus nine totals. This is seventeen flips (26-9) faster than just scanning the whole deck. Right?
Let’s take it one step further and split the individual piles into two groups (one Ace to 6, the other 7 to King). In this case the average search would cut to 6.
This is exactly the power of indexing.
Indexing plays a crucial role especially in applications such as eCommerce websites. Imagine that you are looking to buy a new bag on an ecommerce website. You type in the search query and you expect to see a range of options that you’d like to choose from. However, due to the absence of indexing you are stuck looking a blank screen for the next 15 mins waiting for the relevant data to load or even worse, you get everything ranging from garments to electronics as an answer to your result. Given the number of alternative ecommerce websites on the internet, I highly doubt that you’d be willing to patiently wait around instead of simply logging onto a faster one.
Businesses should take note that this is exactly the point where they end up losing customers. A simple case of no-indexing can prove to be a major leak in the revenue and significantly shrink your bottom lines.
This blog explores Indexing, its architecture, types and how it actually influences speed.
Technically speaking, an index is a copy of selected columns of data from a table that can be searched very efficiently. Although indexing does add some overheads in the form of additional writes and storage space to maintain the index data structure, the key focus of implementing index – in various available ways – is to improve the lookup mechanism.
It must improve the performance of data matching by reducing the time taken to match the query value.
Now, let’s understand how index is actually programmed and stored and what causes the speed when an index is created.
Index entries are also "rows", containing the indexed column(s) and some sort of pointing / marking data into the base table data. When an index is used to fetch a row, the index is walked until it finds the row(s) of interest, and the base table is then looked up to fetch the actual row data.
When a data is inserted, a corresponding row is written to the index, and when a row is deleted, its index row is taken out. This keeps the data and searching index always in sync making the lookup very fast and read-time efficient.
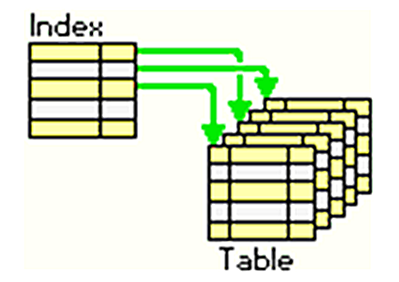
As mentioned earlier, Indexing is implemented using specific architecture and approaches. Some architectures worth mentioning are:
Non-Clustered:
The data is stored in arbitrary order, but the index specifies logical ordering while storing pointers.
Practical Usage : Non-Clustered index are used when the database schema is inherited and entries are not sequenced or structure. The value are store as random or as they are generated. For example, the data received from monitoring sensor at common database. There will be hundreds of such entries coming in at random point. Here a separate non clustered index enables for faster data search.
Clustered:
The index that is storing the datamap or pointers is reflected on hard disk. At times it also alters the physical location of data on hard disk, also called as block. This give tremendous boost when making a lookup for search query.
Practical Usage: Enterprise projects like SAP having very structured data and datamap, but the data size is very huge, will benefit from Clustered index. The query searching the data knows exact disk sector to work on.
Cluster:
This should not be confused with above keyword. Cluster is created when multiple table and database are joined. The records for the tables sharing the value of a cluster key shall be stored together in the same or nearby physical location on hard disk. This reduces latency and approves faster search over complex tables and database.
Practical Usage: An application used to analyse the data or create a report from combination of two or more tables, a compound or cluster will provide this environment. Typically used in data analysis or report generation from multiple tables and database.
Now, let’s glance over the types of indexes:
Bitmap Index:
It is unique and special in a way because it stores the indexing information in bit arrays also called bitmaps. The query and search result is done by performing logical bitwise 0 or 1 operation. This make it very fast. Database having tables with very few unique fields are available for indexing. Plus, the data stored is heterogenous. Also, the data is selected too often with very few insert and update options. Plus, the data stored is as stream of bit 0 or 1.
Practical usage:
A weather station has a huge amount of data; however, it may not have data for every parameter each time. In case you need to look for data of the weather for a day sometime in the last month, you’d have to go through every parameter whether it has an entry or not. Whereas, Bitmap indexing speeds up the process by entirely removing the parameters where there are no entries.
Similarly, in case of the control centre of a pizza joint, it will be very difficult for the control centre to check the fulfilment of orders across the pizza joints in a particular city.
Dense Index:
This index is a file with pairs of keys and pointers for every record in the data file. Every key in this file is associated with a pointer to a record in the sorted data file.
Practical Usage:
Can you imagine looking up a Canadian city in a database that has cities from across the globe? That would be huge amount of data to go through. Dense Index stored on a separate file, helps in this case as it retrieves data faster based on keywords. However, dense index can cause files to become huge, so take caution that the file size is small than available memory size.
Sparse index:
It enables physical address specific search. Here index is a file with pairs of keys and pointers for fewer block in the data file. Every key in this file is allied with a pointer to the block in the sorted data file, but is with fewer pointer to give the starting searching point.
Practical Usage:
In this case, Sparse index makes life of an inventory manager much easier by enabling lesser mapping by having a logical storage in terms of alphabets or numerical order. The Sparse Index can map exactly what to look for and what to pass.
Moreover, the sparse mapping will help to know the query to start with. In a use case the catalogue starting with W knows which diskspace to begin.
Reverse index:
It simple reverses the value before entering into the file, for eg 1234 will be stored as 4321. It is especially useful for indexing data such as sequence numbers, where new key values increase monotonically.
Practical Usage:
As the name suggests, the reverse index enables you to look for the data in the latest entries first and starts looking up for information backwords. This is especially beneficial in terms of the business development data that you may need in order to reach out to the recently contacted prospects first.
Conclusion
To summarize, an index is used to speed up searching in the database. Fairly all databases like file base, in-memory or relational database all implement and provides well documented way to harness the power of indexing and shorten the query time.
Ultimately, speed is one of the defining factor of not just successful products but businesses as well. The goal of implementing indexing is to crank up the speed of the application, thereby sealing off all the possible revenue leaks.
If you aren’t too sure about how to go about indexing for your application. We can help!
Author

Vinit Sharma - Technical Architect
Vinit Sharma, a seasoned technologist with over 21 years of expertise in Open Source, cloud transformation, DevSecOps strategy, and software architecture, is a Technical Architect leading Open Source, DevOps, and Cloud Computing initiatives at Clarion. Holding certifications as an Architect and Business Analyst professional, he specializes in PHP services, including CMS Drupal and Laravel, contributing significantly to the dynamic landscape of content management and web development.


